
COMPARTE
En este artículo vamos a aprender como es posible que los ciberdelincuentes sean capaces de conectarse a cualquier ordenador sin dejar ni rastro y de rebote, vamos a tratar el tema de la famosa frase: ¿Quién va a querer hackearme?. No soy nadie importante.
Antes de entender como es posible saber quién está al otro lado de una conexión en Internet, debemos entender algunos fundamentos de como funciona esta red. No os asustéis, no vamos a entrar en grandes detalles, solo los suficiente para que nosotros, meros mortales, podamos entender los riesgos que conlleva el simple hecho de conectarse a Internet.
Así que sin más dilación vamos a sumergirnos en el fascinante mundo de las redes de datos. O si lo preferís…. Vamo a vé como funsiona Internes. Ahí es ná!
Direcciones IP
Internet utiliza las llamadas direcciones IP que no son más que unos números muy grandes asociados a cada ordenador que se comunica a través de Internet. Parece una cosa muy complicada no?, pues no lo es. Pensad en ello como vuestro número de teléfono. Si queréis hablar por teléfono, tanto vosotros como la persona a la que llaméis tiene que tener un número de teléfono… sino es imposible llamar a esa persona. Además, ese número es único en el mundo, ya que si hubiera dos iguales no sabríamos a quién estaríamos llamando.
Pues bien, las direcciones IP son los números de teléfono de los ordenadores de Internet y absolutamente todos los ordenadores que hablan en Internet tienen una de estas direcciones IP y esa dirección IP es única en todo el mundo. Lo mismo que los teléfonos.
Hay dos tipos de direcciones IP conocidos como IPv4 e IPv6 (la versión 4 y la versión 6), si bien, la versión cuatro sigue siendo la más habitual. De la misma forma que tu número de teléfono esta formado por un número de 7 a 11 dígitos (normalmente), las direcciones IP están formadas por 4 números separados por puntos, pudiendo tomar, cada uno de esos cuatro números, un valor entre 1 y 255. Así 142.250.179.206 es una posible dirección IP, en concreto una de las usadas por Google. Raramente veréis estas direcciones, pero bueno, ahora ya sabéis la pinta que tienen.
Así que los fundamentos pintan bien. Cualquier cyberdelincuente haciendo maldades en Internet debe usar una dirección IP única que lo identifica, así que no debería ser tan complicado localizar a esa persona. Veremos que, si bien eso es cierto, estos señores complican el proceso de tal forma que en la práctica, averiguar esa dirección IPs puede resultar bastante complicado.
Tipos de Acceso a Internet
Podríamos decir que hay dos tipos fundamentales de direcciones IP en Internet, o si lo preferís, dos tipos de ordenadores conectados a internet.
En primer lugar tenemos los ordenadores directamente conectados a Internet que tienen una dirección IP real para ellos solos. Este es el caso de los servicios que usáis en Internet normalmente: buscadores, IAs, periódicos on-line,… Y normalmente también el de vuestro teléfono móvil. Sí. Si tu teléfono está conectado con datos, tendrá una dirección IP única, y cualquiera que la conozca podría, potencialmente, acceder a él.
En segundo lugar tenemos los ordenadores que se conectan a esos servicios. Esto es nuestro ordenador en casa, cualquier dispositivo conectado a nuestra wifi (o red local -LAN_ si lo preferís), nuestro tablet, teléfono, consola, TV…. Como os dijimos antes, todos ellos deben tener una dirección IP única para poder usar Internet, sin embargo, en estos casos, esa dirección única es compartida por todos los dispositivos en nuestra casa.
Podéis pensar en estos como en las extensiones privadas de una empresa que usa su propia PBX o centralita telefónica. Para hacer llamadas internas podéis marcar simplemente la extensión con la que queréis comunicaros, pero desde el exterior tenéis que llamar a la centralita para que os pasen con la extensión que queréis (suponiendo que no es una de esas que exponen los número internos). De la misma forma, cuando alguien llama desde el teléfono de su oficina, esa llamada pasa por la centralita (pulsando el doble 0 típicamente) y el que recibe la llamada verá el número de teléfono de la centralita y no el de la extensión interna… puesto que ese número no existe en la red telefónica… solo internamente en esa empresa. Por esa razón los números de extensiones no son únicos en el mundo, pero si únicos en una determinada centralita. La extensión 123 en la centralita de el Banco Dameloto y la centralita de la compañía Yameloquedoyo tienen el mismo número de extensión, pero se trata de dos teléfonos totalmente diferentes… y aún así ambos pueden comunicarse usando sus respectivas centralitas.
Las direcciones IP tradicionales (lo que se conoce como IPv4) son unos números que nos permiten representar unos 4 mil millones de ordenadores. Eso es una barbaridad, pero si tenemos en cuenta que cada uno de nosotros en nuestra casa tenemos una porrada de cosas conectadas a internet…. Un teléfono, un tablet, un ordenador, la televisión… eso ya suman 4 dispositivo por persona por lo cual ya solo mil millones de personas podrían conectarse a internet, lo cual es mucho menos que la población mundial. Si a esto añadimos los servicios que usamos, esto es, IPs utilizadas por compañías, el número todavía se reduce mucho más. Por esta razón los dispositivos caseros suelen compartir una única IP.Sin embargo, con eso no es suficiente y existe desde hace ya algún tiempo unas direcciones IP más grandes que permiten representar muchísimos más ordenadores, usando número más grande. Estas direcciones se conocen como IPv6, si bien, su uso todavía no se ha popularizado tanto como la versión anterior (IPv4).
Cuando os conectáis a Internet desde vuestra casa o desde alguna wifi pública, la dirección con la que se os conocen en Internet es la dirección del vuestro router (o el de la wifi que estéis usando). El router es el que tiene una dirección IP única en Internet, La que todos los dispositivos conectados a él usan para acceder a Internet. Siguiendo con nuestro símil telefónico, el router es tu centralita para usar internet.
El router hace un truco conocido como NAT (Network Address Translation o Traducción de Direcciones de Red) con el que es capaz de saber si los datos que recibe pertenecen a un dispositivo u a otro. Básicamente lleva la cuenta de que dispositivo se ha conectado a donde, y cuando recibe algo de un determinado servidor en Internet, comprueba que dispositivo estaba hablando con ese servidor y le envía los datos. En la práctica el proceso es un poco más complicado (que pasa si dos personas en casa están conectados al mismo servicio?), pero conceptualmente así es como funciona.
Dicho esto, toda dirección IP existente en Internet está asociada unívocamente a una única persona o entidad.
La dirección IP del router de tu case está asociada a tu nombre a través de un contrato con tu proveedor de Internet. Es muy difícil, sino imposible, obtener una conexión a Internet doméstica sin proporcionar datos personales. Por lo tanto, cualquier conexión que hagáis desde vuestra casa estará asociada a una dirección IP, que estará asociada a un determinado proveedor de Internet, el cual posee tus datos personales para poder enviarte la factura todos los meses.
Lo mismo sucede con las wifis públicas. Es exactamente el mismo caso, solo que la conexión a internet suele estar asociada a una empresa en lugar de una persona, pero lo que si es conocido es quien paga por esa conexión y sus datos personales, los cuales suelen incluir una dirección física.
En resumen, una vez que conoces la dirección IP de alguien, preguntando a la persona adecuada (esto es tu proveedor de internet) puedes averiguar fácilmente en dónde se encuentra esa persona. Al menos para las conexiones fijas… con los móviles la cosa es solo un poquito más complicada y veremos en un momento como funciona.
Otros tipos de acceso
Cuando accedemos a Internet desde alguna wifi pública, nuestras conexiones utilizarán la IP del router que controle esa red. Por lo tanto, cualquier conexión que realicéis desde una red de ese tipo se verá en el exterior como una conexión desde la IP del router que está asociado a la entidad/negocio que te ofrece la wifi gratis (un hotel, una cafetería,…). Con lo cual cualquiera de esas conexiones se pueden rastrear al menos hasta el lugar desde donde se inició.
Imaginemos una cafetería por ejemplo. Una conexión desde la wifi de esa cafetería se puede rastrear fácilmente hasta la cafetería. Dependiendo de lo que haya hecho esa persona, una orden judicial para obtener las imágenes de las cámaras de vigilancia (que prácticamente todos los locales tienen hoy en día) y habremos obtenido una lista de unos pocos sospechosos.
Otra forma de poder acceder a Internet podría ser utilizando un teléfono configurado como router (la opción de compartir wifi que todos conocéis). En este caso, las autoridades pueden fácilmente asociar la dirección IP de una conexión con una determinada red móvil y proveedor de servicio, el cual puede ser requerido para proporcionar información sobre ese terminal.
Si el terminal tiene un contrato, lo persona que realizó la conexión ya estaría localizada. Si la persona, compró un teléfono pre-pago en una tienda sin cámaras de vigilancia y pagó en efectivo. En ese caso, las autoridades pueden localizar el terminal, pero no tienen forma de asociarlo directamente a una persona en concreto. Lo que si pueden es determinar la ubicación física aproximada del teléfono usando triangulación con lo cual si un atacante permanece demasiado tiempo conectado desde un mismo lugar podría ser capturado físicamente o habría más posibilidades de que alguna cámara de vigilancia lo grabe, ofreciendo más facilidades para identificarlo. Vamos, que no es necesario que tengáis conectado el GPS para que sepan donde estáis.
Se trata de un proceso de radiolocalización, es decir, de localizar algo usando ondas de radio. El proceso es sencillo y necesita, normalmente 3 receptores. Imaginad un teléfono encendido en un determinado punto. El teléfono, está continuamente enviando una señal que las antenas de telefonía móvil desperdigadas por ahí pueden recibir. Las ondas electromagnéticas tienen la peculiaridad de que se atenúan, es decir, pierden potencia. O si lo preferís, cuanto más lejos están, más bajito se oyen. Así que es posible estimar la distancia a la que se encuentra un teléfono de una antena, simplemente por la potencia recibida (lo alto que se oye al teléfono).
Algo parecido a lo que nosotros hacemos con el sonido y nuestras dos orejas.
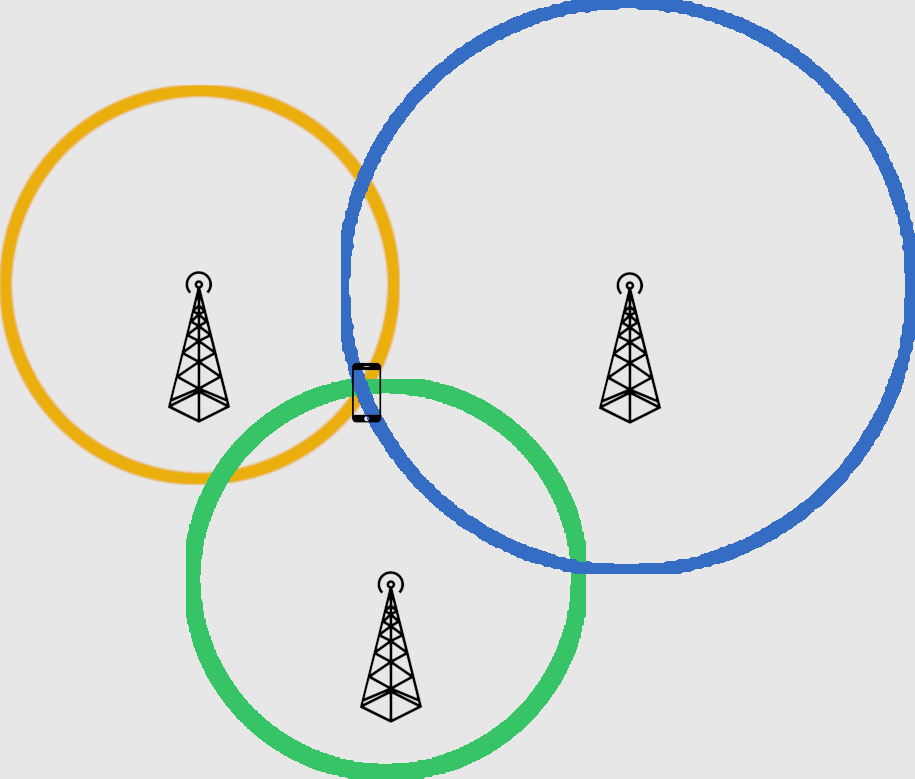
Imaginemos que tenemos tres antenas. Las llamaremos 1, 2 y 3. Si la antena 1 recibe una determinada potencia del teléfono y determina que se encuentra a 1 Km de distancia, sabremos que en un radio de 1Km en torno a la antena 1 podremos encontrar el teléfono. Sin embargo, eso es un círculo muy grande. Lo que hacemos es ahora tomar la antena 2 y repetir el proceso. Si las antenas están relativamente cerca, los dos círculos que obtendremos se cortarán en, normalmente 2 puntos. Esos son los dos puntos en los que el teléfono potencialmente se encuentra. Utilizando una tercera antena, podremos averiguar cual de los dos puntos es el correcto. Voilá…. ahí lo tenéis… triangulación!
Así que por ahora, esta sería la técnica más anónima para conectarse a una ordenador en Internet. Sin embargo, un cyberataque sofisticado no se realiza en 5 minutos, puede llevar horas, días o incluso semanas, con lo cual esta ultima opción de usar un teléfono móvil por un tiempo prolongado tampoco es ideal, ya que daría tiempo a las fuerzas del orden para localizar al ciber delincuente y personarse físicamente en esa ubicación.
_NOTA:En el artículo hablaré normalmente de ciber delincuentes,ya que este es quizás el caso más común en nuestra sociedad, sin embargo, podemos fácilmente pensar en otros escenarios con regimenes represivos en los que los papeles se tornan y los que intentan no ser localizados son los buenos, y los gobiernos o fuerzas del orden tienen unos motivos más cuestionables…. Buenno, quizás esto no sea tan raro en nuestra sociedad tambpoco.
Proxies y VPNs
Cuando se trata de mantener la privacidad y anonimato, palabras como proxies, VPNS saltan inmediatamente a la palestra. Veamos en detalle como funciona cada una de estas tecnologías para comprender las implicaciones de utilizar una u otra desde el punto de vista del anonimato.
Un proxy no es más que un ordenador (realmente un programa que se ejecuta en un ordenador) al que nos podemos conectar y pedirle que nos redirija a otro ordenador distinto. El ordenador final verá la dirección IP del proxy, en lugar de la dirección original desde la que nos conectamos. Siguiendo con nuestro símil de los teléfonos, un proxy sería un colega que tiene dos teléfonos. Cuando lo llamamos le decimos que nos gustaría conectar con un determinado número. Nuestro colega marca el número en el otro teléfono y conecta los dos terminales con cinta para que lo que nosotros digamos se envíe al segundo terminal y lo que se oiga en el segundo terminal se envíe al primero… Voila, proxy telefónico cutre.
Desde este punto de vista, el usuario permanece anónimo, al menos desde el punto de vista del ordenador destino. Sin embargo, el proxy, muy probablemente, mantendrá registro de las conexiones entrantes y saliente de tal forma que es cuestión de pedir al proxy esta información para obtener la dirección de origen y localizar al usuario responsable de la conexión. Si bien, se dice por ahí que hay proxies (y VPNs) que no mantienen logs (que no mantienen registro de las direcciones de los que se conectan a ellos), eso es bastante improbable hoy en día con el tipo de legislación que está aprobando la mayoría de países. Por supuesto, puede existir, pero se trataría de servicios que probablemente desaparezcan rápidamente en cuanto comiencen a ser populares.
Los proxies, tienen una propiedad muy güay y es que se pueden encadenar. Pensad en el ejemplo de los teléfonos, podéis pedirle a vuestro colega que llame a otro colega con dos teléfonos y repetir el proceso. El usuario se conecta al primer proxy, y en lugar de pedirle que lo conecte a la máquina que quiere alcanzar, le pide que lo conecte a un segundo proxy. Este proceso lo puede repetir varias veces creando lo que se conoce como una Cadena de Proxies (Proxy Chain en inglés). Hay herramientas para hacer esto automáticamente y probablemente os resulte familiar de las películas cuando están intentando encontrar al ciber terrorista malvado (o era el héroe de la peli?) y empiezan a mostrar un montón de saltos en un mapa del mundo, mientras los técnicos escriben frenéticamente en los teclados… Siempre me he preguntado que es lo que escribirán?….
Utilizar una cadena de proxies no asegura el anonimato, pero hace mucho más complicado encontrar el origen de la conexión. Especialmente si los proxies están en distintos países en los que no hay acuerdos de colaboración en materia de seguridad. En estos casos, el país final debe pedir al país del último proxy los logs, para darse cuenta, al conseguirlos, que el origen no es más que otro proxy en otro país con el que debe repetir el proceso. Como podéis imaginar esto dificulta y sobre todo ralentiza enormemente el proceso de localizar el origen de un ataque. Hay que decir que en la actualidad hay sistemas de vigilancia que facilitan este proceso usando técnicas de asociación de tráfico y similares que permiten asociar un cierto tráfico de entrada con un cierto tráfico de salida sin prestar mucha atención a lo que ocurre entre medias, pero bueno. Pilláis la idea no?
El Huevo del Cuco de Clifford Stoll, es un fantástico libro sobre seguridad informática que cuenta la historia de una brecha de seguridad en los albores de Internet. No os voy a contar más, pero si os diré que en el libro se relatan las dificultades del protagonista para poder identificar el origen de las conexiones. Si bien, el libro está ambientado a mediados del los 80, y muchas cosas han cambiado desde entonces, el escenario que describe de la época es muy realista. Una lectura obligatoria para los amantes de la ciberseguridad.
Una VPN (Virtual Private Network) es como su nombre indica una red virtual. En este caso nos conectamos a una máquina remota usando un determinado programa, y desde ese momento es como si estuviéramos conectados directamente en otra red, lo que, entre otras cosas implica que nuestra dirección IP estará determinada por esa red a la que nos conectamos. Todos los datos, desde nuestro ordenador al servidor VPN están cifrados y nadie en ese tramo puede verlos, lo que suele implicar o a tu proveedor de Internet o a la cafetería que ofrece la wifi gratis. Por esa razón una VPN es una buena solución para mantener nuestra privacidad (que no anonimato) al acceder a internet desde redes públicas, ofreciéndonos cierta protección incluso ante wifis maliciosas.
Como sucede con los proxies, los servidores VPN mantienen registros de las direcciones IP de origen y la nueva IP que les asigna, con lo cual desde el punto de vista de localizar el origen de una conexión, se comportan de la misma forma que un proxy.
Las diferencia principales entre un proxy y una VPN son las siguientes:
- Los proxies solo se pueden usar para conectar a servicios estándar como la web y por lo tanto hay ciertas cosas como escaneos de puerto sigilosos que no se pueden hacer a través de un proxy o una cadena de proxies. En una VPN por el contrario podemos, al menos técnicamente, hacer lo que queramos.
- Precisamente por esta razón, las VPN se suelen utilizar para acceder a servicios que imponen restricciones geográficas. Como servicios de streaming que solo funcionan si te conectas desde un determinado país. Los servicios VPN suelen ofrecer una variedad de servidores en distintos países que puedes utilizar. Una vez conectados, es como si estuviéramos en la red de ese servidor, la cual está en un determinado país. Recientemente estos servicios de restricción geográfica empiezan a mantener listas de direcciones IPs asociadas a servicios VPN para evitar este tipo de acceso.
- La comunicación entre el origen y el servidor VPN suele estar cifrada, de forma que en ese tramo nadie puede ver el tráfico (el contenido de los datos). Los proxies por el contrario puede que cifren esa conexión o puede que no. Sin entrar en complicaciones, si para acceder al proxy tenemos que usar una url del tipo https la conexión estará cifrada. En caso contrario no lo estará. Tras el proxy, el cifrado dependerá del servicio al que queramos acceder, una vez más, si estáis intentando acceder a una web usando https los datos estarán cifrados, pero en otro caso no, suponiendo que todos los proxies en la cadena soporten HTTPS y lo utilicen para establecer las conexiones intermedias.. Existen más casos, que el uso de https, así que tomad el párrafo anterior como un ejemplo y no como la verdad absoluta.
Redes ORB
Como acabamos de contaros, la mayoría de servicios proxy o VPN existentes van a mantener logs de quien se conecta y a donde lo hace. Pero que pasaría si esos proxies y VPNs no pertenecieran a negocios legales?. En ese caso sería más que viable que no exista ningún tipo de registro de las conexiones realizadas a través de tales servicios. Al menos eso sería una forma de promocionar esos servicios en ciertos ámbitos.
Pensemos en el siguiente escenario. En lugar de contratar algún tipo de servicio en el que correr proxies sin logs, que os parecería la idea de hackear dispositivos a lo largo y ancho del mundo, instalando algún programa en ellos con el que utilizar esos dispositivos para nefastos propósitos como facilitar el ataque anónimo a algún servicio online?. Eso si es una pregunta larga eh?.
Una red ORB (Operational Relay Box, o Máquina de retransmision operativa) es precisamente eso. Alguien se ha dedicado a hackear ordenadores, routers, dispositivos IoT, teléfonos,… y ha instalado en ellos un software con el que dirigir conexiones de unos nodos a otros, de forma que sea muy complicado averiguar de donde viene una conexión.
Estas redes ORB tienen algunas características que las hacen únicas.
- Están distribuidas geográficamente. Cada uno de esos ordenadores comprometidos puede estar a tomar por saco.
- Son fácilmente reconfigurables o dicho de otra forma, es fácil modificar el camino que sigue tu conexión a través de los dispositivos infectado, permitiendo cambiar fácilmente el nodo de salida (o el último nodo de la cadena)
- Los nodos de entrada y salida desaparece cada 60 o 90 día lo que dificulta su detección a largo plazo.
- Las redes ORB en ocasiones incluyen servicios contratados legalmente (VPS -Virtual Private Server o Servidor Privado Virtual- normalmente que permiten instalar cualquier tipo de SW) que se utilizan junto con dispositivos hackeados.
Como podéis ver hay muchas similitudes con una BotNet tradicional, si bien, el objetivo final es diferente. En lugar de conseguir que muchas máquinas hagan una cosa a la vez, la red ORB interconecta máquinas para formar un laberinto que los investigadores deben desenmarañar para encontrar al responsable de un determinado ataque.
Como os podéis imaginar este tipo de redes las crea poco a poco algún tipo de organización, normalmente maliciosa, con el objetivo de alquilar sus servicios a cyberdelincuentes de forma que no tengan que hackear ellos mismos ese gran número de dispositivos. Este tipo de servicios son los que se contratan en la Darknet y sí, son un negocio rentable.
DarkNet y Tor
Además de usarse para alquilar/vender servicios o productos de dudosa legalidad, la Darknet o Red Oscura se puede utilizar para preservar el anonimato. La Darknet es un sitio chungo que da mucho miedo, si bien es cierto que también puedes encontrar cosas que dan mucho miedo en la web normal. Pero lo que nos interesa a nosotros de esta red es el proyecto Tor (The Onion Router o el router de la cebolla).
Tor es un proyecto que implementa una red virtual sobre Internet
utilizando un protocolo llamado onion (si, cebolla, por que
tiene muchas capas… como Shrek). Este protocolo fue diseñado para
asegurar el anonimato de los usuario. Sin entrar en detalles, utiliza
criptografía y su propia forma de enrutado para mover la información de
uno ordenador a otro. Cada ordenador en la ruta del mensaje solo conoce
el ordenador anterior, del que recibe el mensaje, y a que ordenador debe
enviar la información, pero no tiene forma de saber de que ordenador
viene el mensaje o a que ordenador va.
La red Tor está formada también por ordenadores que ejecutan un determinado programa. Ese programa permite enviar datos desde ordenadores que lo ejecutan. La forma de enviar los datos es a través de Internet, pero en lugar de seguir el camino normal de la información en Internet, ellos deciden a través de que ordenadores se van a enviar los datos. Por eso se dice que es una red virtual sobre Internet. Es como Internet, pero en lugar de usar cables, usa Internet.
Si bien, el tráfico entre nodos Tor se puede ver, y es posible crear tu propio nodo Tor con lo que al menos, puedes ver cual es el siguiente nodo Tor al que se dirigen los paquetes que pasen por tu nodo, no es posible, al menos no de forma sencilla, determinar que tráfico pertenece a quién ya que el origen solo lo conoce el nodo inicial y el destino solo lo conoce el nodo final. Y cada nodo no sabe que posición ocupa en la cadena.
El proyecto Tor se puede utilizar para acceder a servidores dentro de la red Tor (Si, existen varios servicios legales que se pueden acceder a través de DarkNet como por ejemplo el New York Times) o para acceder a la web normal. En este último caso, la información de origen se enruta a través de la red Tor hasta lo que se conoce como un nodo de salida. En ese punto , el mensaje deja la red Tor y entra en Internet. Al igual que sucede con los Proxies y las VPNs, a partir de ese punto, cualquier actividad se verá con la IP del nodo de salida, pero a diferencia de los primeros, ese nodo de salida no tiene ni idea de a quién pertenecen los datos.
Técnicamente, cuando accedemos a un servicio web usando la red Tor se crea un circuito aleatorio de tres relés: Un nodo de entrada, un nodo intermedio y un nodo de salida. Ese camino se establece de antemano y es el mismo utilizado para enviar el tráfico de vuelta al origen sin conocer la dirección del ordenador que inició la conexión. Para el sitio web, la conexión parece venir del nodo de salida de la red Tor. Para el nodo de salida, los datos de ese servidor web están asociados a un determinado circuito que le dice cual es el nodo intermedio, el cual sabe cual es el nodo inicial…
Cuando accedemos a servicios onion en la Darkweb, el número de relés Tor se incrementa a seis. Tres utilizados por el que accede al servicio y tres utilizados por el servicio. Técnicamente es posible utilizar más de 3 relés, sin embargo en la práctica es una tarea bastante complicada.
Como podéis ver, los puntos críticos de este protocolo están en la entrada y la salida de la red. Los delincuentes que hacen negocios en la DarkWeb no necesitan salir, usan los servicios dentro de la red Tor, pero un cyber ataque a un servicio digamos normal, requiere dejar la red Tor para poder acceder al servicio que desean atacar o acceder.
Este punto débil se ha utilizado en el pasado para identificar usuarios en la red Tor, añadiendo nodos a la red bajo el control de los que quieren hacer la identificación y correlando tráfico de entrada y tráfico de salida de la red. Así que, aunque Tor añade una sólida capa de anonimato, si no se usa con cuidado puede desvelar más información de la que podría parecer a simple vista.
Por último deciros que no hay nada ilegal en conectarse a la DarkNet o si lo preferís no hay nada ilegal en usar el proyecto Tor para acceder a Internet o a servicios legales en la DarkNet. Lo que es ilegal es cometer crímenes. Sería algo así como si fuera ilegal pasar por un determinado barrio porque se venden drogas. Si vendes o compras drogas estás cometiendo un delito, pero si solo caminas no. Otra cosa es que te apetezca pasar por uno de esos barrios.
Huella Digital de los Usuarios
Hasta el momento hemos hablado de los detalles técnicos de localizar una determinada conexión, o mejor dicho el origen real de una determinada conexión. Sin embargo, si bien la tecnología puede hacer muy,muy difícil este proceso, esto solo es cierto suponiendo que se ha realizado siguiendo de forma estricta lo que se conoce como OPSEC. Aunque el término tiene un origen militar, se ha popularizado en el mundo de la ciberseguridad con un significado adaptado a este entorno.
OPSEC es la contracción de OPerations SECurity (Seguridad de Operación) y no es más que una serie de reglas que debes seguir para asegurar un determinado nivel de seguridad. Tu OPSEC puede ser tan sencillo como usar claves largas con número, letras y caracteres especiales o llegar a nivel paranoico en el que cada conexión se realiza utilizando un perfil digital desechable a través de conexiones cifradas desde lugares diferentes cada vez.
Sin una OPSEC adecuada, todas las técnicas descritas anteriormente son totalmente inútiles. Veamos esto con un sencillo ejemplo, y esto es algo que ha pasado en el mundo real y que pasa a menudo con principiantes en el mundo de la seguridad. Imaginad que un super ciber delincuente va a cometer algún tipo de maldad. Se conecta usando Tor desde una wifi publica en un lugar sin cámaras de seguridad. Una vez que todo esta configurado va y mientras espera a que su víctima esté en línea comprueba su correo en Google… Boom, automáticamente su IP actual se asocia a una cuenta de correo de una determinada persona. Lo mismo sucede si se va a YouTube a ver videos usando su cuenta para no aburrirse o sube una captura de pantalla de su defacement a su cuenta de Instagram…. Eso es lo que se conoce como una mala OPSEC.
Sin embargo, estos casos son bastante obvios, pero las cosas son incluso más complicadas. Desde hace algún tiempo, especialmente compañías que se dedican a espiar (no necesariamente los tipos malos… bueno, técnicamente si serían tipos malos) utilizan lo que se conoce como Browser Fingerprint o huella de browser. Hasta hace poco, sitios web como Amazon, facebook o google utilizaban cookies para identificar a los usuarios. Luego utilizaban tracking pixels (o pixels de traceo). Incluso si no hacías login en los servicios, ellos sabían que eras tu porque tu browser tenía una cookie que ellos habían puesto ahí, o habían almacenado un perfil basado en accesos anteriores.
Una cookies es simplemente un valor que se almacena en tu browser y que cualquier servidor puede consultar cuando te conectas a él. Las cookies tienen un nombre y un valor. Por ejemplo, si visitáis nuestra web y aceptáis las cookies el sitio web creará una cookie llamada
roor-blog-cookie-acceptedcon el valor 1. De esta forma, la próxima vez que os conectéis sabemos que no tenemos que mostrar el banner de aceptar cookies. Cuando hacéis login en un determinado sitio el sitio almacena una cookie en vuestro browser para recordaros y que no tengáis que hacer login otra vez.Las cookies tienen una fecha de caducidad. Algunas expiran en unos pocos minutos y otras pueden durar meses dependiendo de su naturaleza.
Así que borrando las cookies o usando el modo incógnito del browser podías más o menos evitar que te siguieran. Los aguilillas se dieron cuenta de eso y comenzaron a utilizar lo que se conoce esas huellas de browser. Básicamente lo que hacen es ejecutar cierto código javascript en tu browser para extraer suficiente información local que te diferencia de otros usuarios. Cosas como el tipo y versión de tu browser, tu tarjeta gráfica, fonts instalados, resolución de pantalla… y cosas todavía más peregrinas. Con todo eso crean un huella digital que, cada vez que te conectas a su sitio les van a permitir identificarte. Quizás no sepan tu nombre (si nunca has creado una cuenta), pero saben que eres tú, cada vez que te conectas y por eso sigues viendo los mismos tipos de videos en YouTube aunque no te hayas registrado o hayas salido de tu cuenta, o la web de los vuelos sigue subiendo el precio aunque te conectes en modo incógnito.
Ya existen browser como Brave que incluyen opciones para ofrecer variaciones de estos datos de forma que el cálculo de la huella digital sea distinto cada vez y no puedan saber que es la misma persona la que se está conectando a un determinado sitio. Estamos ansiosos por ver cual será el siguiente paso de los espías legales.
Ocultándose al descubierto
Ahora que sabemos como funciona todo esto de localizar a un cybercriminal y las opciones disponibles, llegamos al punto clave de este artículo. La respuesta a la pregunta:
No soy nadie importante. ¿Por qué me iban a hackear a mi?
La respuesta es muy sencilla. ¿Cuál es el problema de todos las técnicas que hemos visto?. Los registros de la actividad, así que la única forma de asegurar el anónimato completamente es eliminar esos registros. Eliminar los registros de un servidor proxy o VPN no es fácil. Se trata de servicios expuestos a internet que tendrán un cierto nivel de seguridad. Al menos un nivel de seguridad más alto que el que tiene Juanito en su ordenador en casa o en su teléfono móvil.
Así que, ¿Qué es lo que haríais vosotros?. Intentar hackear el servidor de VPN bajo vigilancia para borrar vuestros logs, o hackear el móvil o ordenador de cualquiera, limpiar tu rastro e instalar un proxy en él, configurado por vosotros mismos para que no almacene ningún tipo de registro?… La opción 2 es mucho más fácil y sobre todo discreta.
Pues bien, esta es una de las razones de peso por la que un cyberdelincuente estaría interesado en hackear vuestro teléfono u ordenador. No para robar vuestros datos, sino más bien para usaros de chivo expiatorio.
Precisamente por esta razón es importante que tengáis un mínimo de seguridad que complique esta tarea. En este escenario, el cyber delincuente no tiene un interés especial en vosotros más allá que la facilidad para usar vuestros dispositivos… Si se lo ponéis un poquito más difícil que la mayoría de la gente, hay muchas probabilidades de que pase de vosotros y se vaya a por la siguiente víctima. Después de todo, para que va a perder el tiempo con tu sistema que es más difícil de hackear cuando puede usar el siguiente que se hackea solo…
Un efecto secundario de todo esto se deriva de la proliferación de herramientas de escaneo y ataque automático. Hoy en día los tipos malos no van probando uno por uno a ver quien está actualizado y quien no. En la actualidad utilizan herramientas automáticas que escanean grandes rangos de direcciones buscando sistemas susceptibles de ser explotados utilizando vulnerabilidades conocidas y accediendo automáticamente a ellos para la tarea que sea que necesitan. Lo que puede incluir intentar robar información bancaria u otros datos…. después de todo es un proceso automático, así que porque no aprovecharse?
Si el vuestro es uno de esos sistemas que no se actualiza nunca, esas herramientas automáticas podrán fácilmente comprometerlo y disponer de él para utilizarlo a su antojo.
Anonimato Absoluto
Así que con todo lo que os hemos contado cual sería la configuración para acceder a Internet de la forma más anónima posible?. Vaya, otra pregunta extremadamente larga :).
Por ejemplo:
- Hackear un número razonable de dispositivos privados a lo largo del mundo. Como decíamos con los proxies si los dispositivos están en distintos países aún mejor ya que el intercambio de datos entre países puede ser más complicado. Alternativamente el delincuente podría contratar los servicios de alguna red ORB en la DarkNet, sin embargo, hacerlo uno mismo ayuda a pasar desapercibido más fácilmente y el hecho de realizar una transación en la Darknet (o en otro lugar) es una cosa más en la que se puede cometer un error, así que continuaremos la explicación bajo esta premisa.
- Conectarse a una wifi pública en la que no haya cámaras de vigilancia cerca.
- Alternativamente, hackear la wifi de algún lugareño a la que tengas acceso desde un lugar no vigilado (sin cámaras) y poco sospechoso… Un parque por ejemplo o una terraza (en lugar de usar la wifi de la cafetería estarías usando la de una casa cercana).
- Establecer una cadena de proxies/VPNs sobre los dispositivos personales hackeados
- Alternativamente utilizar Tor
Hay que decir que, una conexión como esta, va a ser bastante lenta, así que en mundo real quizás no sea posible aplicar todos las puntos. Pero a efectos didácticos, veamos como funcionaría todo esto.
Pepito Er Siberdelincuente se va a tomar todos los días su café al Sunbucks del centro. Desde la terraza del café ha hackeado la wifi ManoloBombo123 que pertenece a un vecino cercano y por lo tanto a la que puede conectarse desde el cafe. Puesto que ha hackeado esa wifi a conseguido acceso al router e instalado programas para eliminar los registros de sus conexiones. Desde esta wifi establece una cadena usando cuatro dispositivos personales localizados en Iran, Bangladesh, Suiza y Surinam usando un proxy modificado para evitar almacenar ninguna información en ninguno de esos dispositivos. Desde el dispositivo de Surinam, se conecta a la máquina víctima usando la red Tor.
Veamos que sería posible hacer para encontrar a Pepito. La máquina víctima solo verá un ataque desde la dirección IP del nodo de salida Tor. Imaginemos que los investigadores son capaces de correlar tráfico y de alguna forma consiguen la dirección IP con la que Pepito ha entrado a la red Tor.
Observad que esto ya es bastante difícil, pero podría ser posible. La IP que han obtenido, desde la que el atacante se conecto a la red Tor, proviene de un teléfono móvil en Surinam. A primera vista este podría parecer el origen del ataque y todo terminaría ahí. Pero imaginemos, por un instante, que los investigadores consiguen el dispositivo (o acceso a el), lo analizan y descubren el software proxy usado por el atacante. Con lo cual consideran que ha sido hackeado y que el origen viene de algún otro sitio. No tengo ni idea de como van las cosas en Surinam, pero esto en un país como España es un proceso lento en principio. Si alguien tiene detalles sobre esto, mandadnos un mensaje.
Digamos ahora que los investigadores hablan con el proveedor de servicio móvil de Surinam para que analicen el tráfico a ese terminal (puesto que en el dispositivo no hay ninguna pista de desde donde se ha conectado Pepito) y consiguen descubrir que a la hora del ataque se detecto tráfico desde una IP de un ordenador en Suiza. El proveedor de Internet ve esa información, si bien, otra cosa es que se almacene suficientes datos para concluir eso y que permitan a una tercera fuente acceder a ellos. Una vez más deben contactar al proveedor de internet en Suiza para poder obtener la información personal del dueño de ese ordenador. Probablemente el proveedor suizo no de los datos sin una orden judicial internacional que requiera su tiempo para ser tramitada.
El proceso continuaría. Si la máquina víctima digamos que estaba en Estados Unidos, hay posibilidades que el proveedor de Internet de Iran no colabore con los investigadores.
Imaginemos, y esto ya es bastante improbable, que consiguen que Iran colabore y tras analizar el tráfico del dispositivo Iraní determinan una cantidad de tráfico inusual de entrada desde una IP en Madrid. Tras contactar al proveedor de Internet de turno (y todos sabemos lo frustrante que esto puede llegar a ser… pulse 1 para facturas, pulse 2 para contratación… pulse 321 para hackeos) consiguen averiguar que el ataque se originó desde la wifi de ManoloBombo123. En este caso no hay tráfico entrante inusual desde una IP externa así que deben suponer que este es el origen. Puesto que todos los registros relacionados con la conexión de Pepito se han borrado los investigadores no pueden seguir más allá. Supongamos que Pepito no fué super cuidadoso y los investigadores (suponiendo que obtienen acceso al router) determinan que el router fue hackeado. Esto eximiría a Manolo, el dueño de la wifi, pero no daría ninguna pista de quien es el culpable.
Ahora solo quedaría analizar las cámaras de vigilancia de los alrededores (hasta donde la wifi ManoloBombo123 es visible) para intentar ver comportamientos sospechosos. En ese caso, incluso si el SunBucks tuviera cámaras, solo verían a un tal Pepito que va todos los días a tomar su cafe y escribir en su ordenador igual que la mayoría de otros clientes.
Como podéis ver, en una configuración como esta es, muy muy difícil conseguir encontrar el origen del ataque. Incluso encontrando el origen es muy difícil asociarlo a una persona en concreto. Rastrear una conexión como esta implica contactar a varios proveedores de servicios en distintos países, probablemente tramitar ordenes judiciales internacionales y soporte de agencia gubernamentales con los recursos para poder hacer el mapeado de trafico en Tor. Dejando a un lado lo probable o improbable que pueda ser hacer todo eso. Si el coste del ataque no es sustancial, porque habría alguien de llevar tanto trabajo y gastar tanto dinero?
Hay una alternativa ilegal a todo esto que consiste en, una vez que has encontrado la primera IP hacer lo mismo que el atacante… Hackear tu mismo cada una de las máquinas para poder acceder a la información sobre, por ejemplo conexiones en curso y seguir la cadena hasta el origen. Si todos esos nodos intermedias fueron hackeados anteriormente, también podrías serlo de nuevo. Sin embargo, esto es tan ilegal como el ataque ficticio del que hablamos y es algo que no deberían hacer las fuerzas de seguridad de un país democrático.
El manual de las buenas prácticas de los ciber delincuentes establece que una vez que una máquina sea comprometida de debe instalar una puerta trasera y corregir la vulnerabilidad para que ningún otro ciberdelincuente la lie.
Sistemas de Análisis de Tráfico
En la actualidad numerosas firmas de seguridad llevan a cabo análisis continuos de tráfico en internet. Estos análisis se utilizan para detectar campañas de spam, phising, ataques de denegación de servicio, propagación de cierto malware, etc… Y hacen todo esto simplemente analizando el tráfico que pasa por sus ordenadores distribuidos por todo el mundo.
Usando este tipo de análisis, puede ser posible obtener el origen de un determinado ataque de una forma mucho más directa sin necesidad de contactar todos los nodos intermedios para deshacer la maraña de conexiones que el delincuente haya preparado meticulosamente.
Sin embargo, pensad que estos sistemas están pensados para monitorizar campañas de malware, y localizar ciertas amenazas que esperan ver en muchos sitios a la vez. Muchas máquinas conectándose a un número limitado de servidores (para descargar malware por ejemplo como parte de una campaña de phising). Esto no sucede mágicamente, es necesario que se detecte esa actividad inusual para que estos sistemas comiencen a monitorizar algún parámetro.
En otras palabras, que un ataque concreto de Pepito a la compañía X en Arizona se puede advertir usando un sistema de este tipo es como que nos pinchemos con la única aguja que hay en el pajar al sentarnos en el heno. Incluso si se informa del ataque poder obtener el origen del mismo rápidamente es bastante improbable.
Pero como siempre, todo depende del tipo de ataque. Si el atacante usa malware conocido, es posible que una de esas alertas salte fácilmente, puesto que el sistema ya dispone de reglas e información para localizar ese ataque en concreto. Pero si se trata de un ataque de phising específico (Spear Phishing) o simplemente acceder a un determinado ordenador para obtener ciertos datos… Eso muy probablemente pasará inadvertido.
Nótese sin embargo, que utilizar alguno de esos servicios ilegales como una red ORB podría ser contraproducente puesto que eso si es algo que estas compañías de seguridad estarían interesadas en monitorizar y mantener listas actualizadas de los nodos de entrada y salida de esas redes. En caso de que la red estuviera activa durante algún tiempo es posible que esos nodos sean conocidos durante un cierto tiempo (antes de que vuelvan a cambiar) y las posibilidades de localizar el origen de ataque a través de esas redes se incrementa.
Se podría hacer algo más
Si analizamos el escenario anterior, un atacante podría hacer el proceso todavía más complicado. La forma de obtener las direcciones IP de los distintos elementos de la cadena fue pedir a los proveedores que analizaran el tráficos entrante de los dispositivos, lo cual, como ya dijimos, está por ver si se puede determinar a partir de los datos que almacene el ISP o la red móvil (cosa que desconozco).
Así que, en lugar de usar un proxy en los dispositivos personales, digamos que el atacante elige usuarios de algún tipo de servicio como X o Discord. En lugar de usar un proxy, digamos que usa un gateway, un programa que toma datos de esos servicios y los envía a otro canal/usuario de esos mismos servicios de donde el siguiente gateway los recoge. En este caso no habría tráfico entrante al dispositivo, solo tráfico a servicios que el usuario utiliza normalmente. Esto es mucho más difícil de ver a primera vista y añade una complicación extra ya que además del proveedor de turno, será necesario lidiar con una tercera parte para que te den acceso a los mensajes para intentar averiguar cual es el usuario sospechoso y luego obtener los datos de ese usuario de estas compañías.
Si bien, esto haría muy difícil, sino imposible detectar el origen de un ataque, el uso práctico de un sistema como este sería cuestionable, especialmente este último cambio que haría la conexión extremadamente lenta.
El atacante podría además añadir mecanismos de seguridad para eliminar cualquier prueba de hackeo (el software proxy) por ejemplo, en cuanto detecte algún tipo de acceso propio de un análisis forense.
Finalmente, y en el caso de que la víctima decida seguir el camino del mal, hackeando hacia atrás todas las máquinas de la cadena. Un atacante debería monitorizar las conexiones en cada punto de la cadena y cortar la conexión inmediatamente en cuanto detecte algo inusual. Esto rompería la cadena y haría imposible recorrerla de vuelta hasta el origen.
Conclusiones
En este artículo hemos aprendido dos cosas. La primera es como consiguen esos cyberdelincuentes que no los pillen cuando hacen sus fechorías. Hemos visto distintas formas de conseguirlo y sus pros y contras. La segunda es que hay un motivo muy jugoso e interesante para que te hackeen aunque no seas nadie ni tengas información de valor, y es que te pueden usar para mantenerse anónimos durante un ataque de una forma relativamente sencilla, sobre todo si no has protegido tu sistema lo suficiente.
Notad que, si alguien va a hacer esto, tiene muchas posibilidades donde elegir y va a escoger la más fácil. Así que configurar un firewall y ejecutar un buen antivirus puede marcar la diferencia en convertiros en una victima o que el atacante pase al siguiente en la lista que sea más fácil de hackear que tú. Además, haciendo eso contribuiréis a hacer la red un lugar más seguro.
■



Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.