COMPARTE
Saber como usar las distintas herramientas de seguridad disponibles en Internet es, desde luego, una habilidad muy útil. Saber como funcionan esas herramientas, los principios técnicos en los que se basan es todavía más útil, ya que da una visión más global y amplia tus posibilidades de imaginar nuevas formas de solucionar problemas. Pero ser capaz de escribir tus propias herramientas te lleva a un nivel superior. Un nivel en el que desarrollar todo tu potencial y llevarlo al máximo puesto que cualquier nueva idea que se te ocurra la podrás llevar a cabo. Este nivel te convierte en la persona que escribe las herramientas que los demás usan… veis por donde voy no?
Es esta nueva sección de la revista os contaremos como programar vuestras propias herramientas de hacking de forma que alcancéis un profundo conocimiento de la tecnología detrás de ellas. La ventaja de programar vuestras propias herramientas en lugar de simplemente leer como funcionan es que en el proceso tendréis que solucionar problemas y aprender cosas no directamente relacionadas con la herramienta en si, pero que os resultarán muy útiles cuando menos os lo esperéis. Detalles que no merece la pena mencionar en un tutorial de la herramienta, pero que aportan conocimientos valiosos en la práctica.
Así que sin más dilación vamos a comenzar con nuestra primera herramienta de hacking. Un programa para volcar _shellcode_s.
GÜAY. ¿QUÉ ES UN SHELL CODE?
Esa es una muy buena pregunta. Un ShellCode es un fragmento de código máquina el cual, una vez ejecutado, ofrecerá acceso a una Shell o intérprete de comandos.
En esencia se trata de un pequeño programa en ensamblador que es
capaz de ejecutar /bin/sh y que puede ejecutarse desde
cualquier posición de memoria, lo que se conoce como Código
Independiente de la Posición, Código Relativo o como dicen
los anglosajones Position Independent Code o
PIC.
Muchos de los exploits que se usan en el mundo real son pequeños programas que explotan alguna vulnerabilidad para engañar al programa vulnerable y conseguir que ejecute un Shellcode y de esa forma conseguir acceso shell con los privilegios con los que se ejecuta el programa vulnerable.
GÜAY… ¿Y PORQUÉ ESTO ME PUEDE INTERESAR?
Otra buena pregunta. En lugar de darte una sesuda respuesta como antes, te voy a responder con hechos.
Existen distintas bases de datos on-line con exploits para distintas
vulnerabilidades. Una de estas bases de datos es exploit-db
(nombre original donde los haya). Me he ido hasta allí, y después de
descartar los exploits web… que son la mayoría, me he encontrado, por
ejemplo, con este:
LBT-T300-mini1 - Remote Buffer Overflow
Realmente no se si el exploit funciona ya que no tengo acceso a ningún LBT-T300, pero lo interesante de este exploit es su código. Echadle un ojo a las primeras líneas:¨
#include <stdio.h>
#include <string.h>
#define MAX_LEN 256
#define BUFFER_OVERRUN_LENGTH 50
#define SHELLCODE_LENGTH 32
// NOP sled to increase the chance of successful shellcode execution
char nop_sled[SHELLCODE_LENGTH] = "\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90";
// Shellcode to execute /bin/sh
char shellcode[SHELLCODE_LENGTH] = "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80";
void apply_cgi(char *vpn_client_ip) {
(...)Como podéis ver… dejando a un lado el NOP sled podéis ver
una secuencia de números almacenada en una variable denominada
shellcode… Interesante no?
Pues si, muchos de los exploits que encontraréis en Internet ejecutan cierto código que está almacenado como una secuencia de números y a simple vista es difícil imaginar que hace.
Por otra parte, cuando se desarrolla o analiza un exploit para una determinada vulnerabilidad, el objetivo final es ejecutar cierto shellcode que va a estar almacenado en algún lugar como una secuencia de números. Si bien hay formas de convertir estos números en ensamblador, tener una herramienta específica para eso no parece una mala idea.
Así que lo que vamos a hacer es escribir un programa que convierta esas secuencias de números en código ensamblador más fácil de entender para nosotros y que así nos resulte más sencillo analizar la funcionalidad de cierto código o exploit.
DESENSAMBLADO. PRESENTANDO CAPSTONE
El proceso de convertir código máquina (una secuencia de números) en un programa en ensamblador se conoce como Desensamblado (lo contrario de ensamblar es desensamblar no?).
Este proceso es diferente para cada procesador, o dicho de otra forma. Cada procesador interpreta esas secuencias de números de forma diferente y, aunque no es super difícil escribir nuestro propio desensamblador, si se trata de una tarea tediosa. Así que lo que vamos a hacer es utilizar una librería que hace todo el trabajo aburrido por nosotros.
Podríais pensar que usando una librería para desensamblar el código máquina es algo trivial y que este artículo debería publicarse en la sección de Ratas de Biblioteca… pero como veréis en seguida hay algunas cosas que hacer para poder obtener un código ensamblador útil.
Así que lo primero que tenéis que hacer es instalar la librería Capstone en vuestro sistema. Muy probablemente exista un paquete para vuestra distribución, pero os recomiendo que bajéis el código fuente y lo compiléis. Una de las cosas güays de Capstone es que no tiene dependencias, así que su compilación no suele entrañar complicaciones.
Eso es lo que hice yo, y para el código de este artículo utilizaremos la versión 5.0 disponible en su sitio web.
UN DESENSAMBLADOR BÁSICO
Vamos a comenzar escribiendo un desensamblador muy básico. De hecho se trata de una variación mínima del ejemplo en la página web de Capstone.
#include <stdio.h>
#include <unistd.h>
#include <capstone/capstone.h>
int
main (int argc, char *argv[]) {
csh h;
cs_insn *ins;
unsigned char buf[1024*16]; // 16Kb
int n;
size_t offset, count;
size_t j;
/* Lee stdin */
while (!feof (stdin)) {
if ((n = read (0, buf + offset, 1024)) <=0) break;
offset +=n;
}
printf ("+ %ld bytes leidos\n", offset);
/* Inicializa desensamblador para x86_64 */
cs_open (CS_ARCH_X86, CS_MODE_64, &h);
count = cs_disasm(h, buf, offset, 0x0, 0, &ins);
if (count > 0) {
for (j = 0; j < count; j++) {
printf("0x%lx:\t%s\t\t%s\n", ins[j].address, ins[j].mnemonic,
ins[j].op_str);
}
} else
printf("ERROR: Failed to disassemble given code!\n");
cs_close (&h);
}Ahora podemos compilar el programa con algo como:
gcc -Wall -o test01 test01.c -I${PATH_CAPSTONE}/include/ \
-L${PATH_CAPSTONE}/lib/ -lcapstone
Si habéis usado la instalación por defecto,
PATH_CAPSTONE debería ser /usr/.
Nota:En el comando de compilación anterior, `PATH_CAPSTONE la tenéis que definir vosotros o sustituirla por el path que hayáis usado en vuestra máquina._
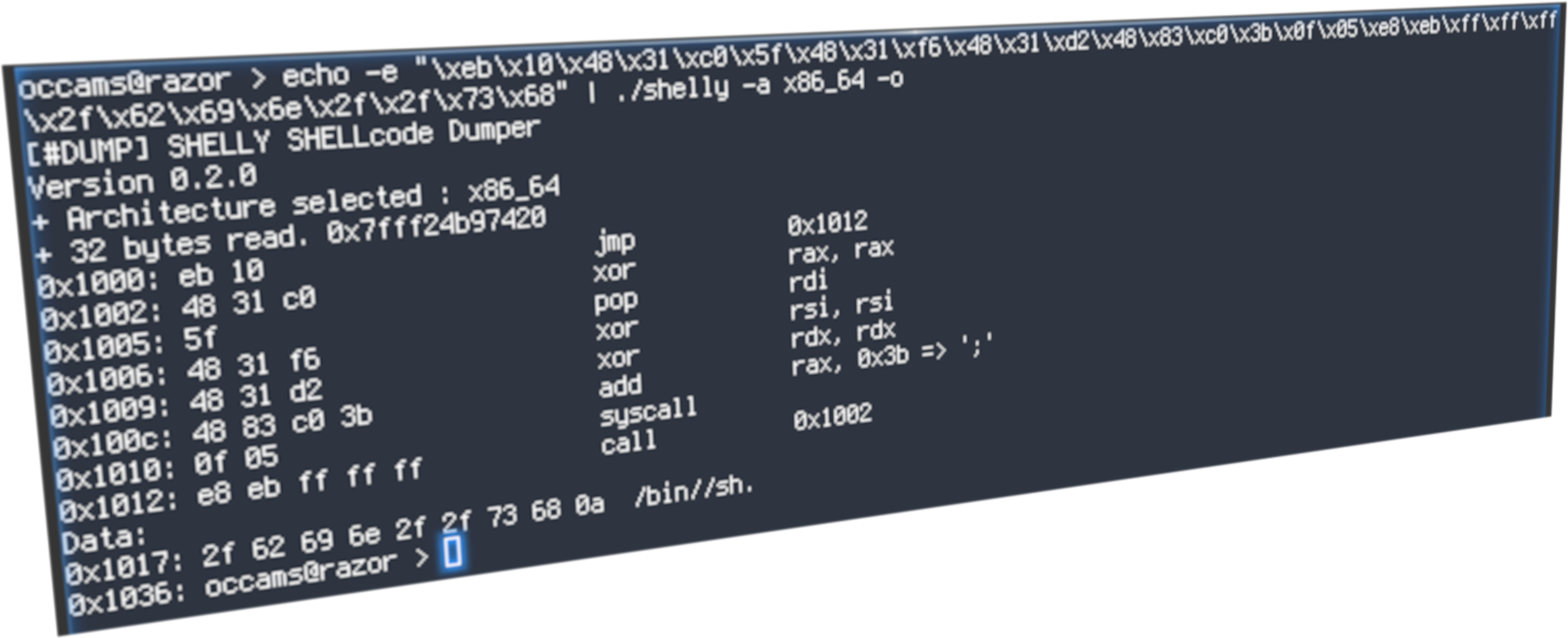
Ahora podemos echarle un ojo al shellcode de nuestro exploit:
occams@razor > echo -e "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\ \x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80" | ./test01 + 24 bytes leidos 0x0: xor eax, eax 0x2: push rax 0x3: push 0x68732f2f 0x8: push 0x6e69622f 0xd: mov ebx, esp 0xf: push rax 0x10: push rbx 0x11: mov ecx, esp 0x13: mov al, 0xb 0x15: int 0x80
Pinta mejor, aunque todavía es difícil imaginar que hace este código. Pero antes de mejorar la salida de nuestro programa veamos como funciona nuestro sencillo programa.
ENTENDIENDO EL DESENSAMBLADOR
Lo primero que hacemos es leer datos desde la entrada estándar de
formar que podamos usar echo, cat u otras
herramientas para pasar datos a nuestro programa.
A continuación inicializamos el desensamblador. Esto lo hacemos con
la función cs_open:
cs_open (CS_ARCH_X86, CS_MODE_64, &h);Como podéis ver, los dos primeros parámetros indican la plataforma y
lo que Capstone llama modo. El modo nos permite definir cosas
como la longitud de palabra (32 o 64 bits) o el Endianess del
procesador (para algunos podemos elegirlo) entre otras cosas. Podéis
consultar el fichero capstone/capstone.h para ver la lista
completa de opciones. El último parámetro es el manejador para
referirnos a esta instancia del desensamblador. Si, podríamos ejecutar
varios desensambladores a la vez aunque no se si eso es de alguna
utilidad.
NOTA:Da la casualidad de que el shellcode de ejemplo que hemos elegido es para 32bits sin embargo, como podéis ver el código generado es perfectamente correcto aún cuando estamos utilizando
CS_MODE_64. En próximas entregas trataremos con estos detalles.
La función cs_open nos devuelve un manejador al
desensamblador utilizando el último parámetro que debe ser pasado por
referencia. En nuestro caso la variable h será el manejador
para esta instancia del ensamblador.
Y una vez que lo hemos inicializado ya podemos desensamblar cualquier
secuencia de opcodes para la plataforma que hemos configurado usando la
función cs_disam.
count = cs_disasm(h, buf, offset, 0x0, 0, &ins);Esta función toma la instancia del desensamblador que acabamos de
iniciar (h en nuestro caso) y le pasa el bloque de memoria
indicado por el segundo parámetro y el tamaño del mismo. En nuestro caso
se trata de los datos que hemos leído de la entrada estándar
previamente.
NOTA:Los datos que pasamos a
cs_disamdeben ser binarios. Si te fijas en los ejemplos estamos pasando el shellcode como una cadena de caracteres pero utilizando el flag-edeechopara que no escape los caracteres e interprete la secuencia\xNNcomo un valor hexadecimal.
El siguiente parámetro es la dirección de memoria que queremos asociar al buffer. Esto nos permite generar código como si estuviera cargado en una dirección de memoria concreta. En este caso estamos pasando cero, con lo cual, la dirección asociada a cada instrucción se corresponde con el offset en el buffer en el que se encuentra dicha instrucción.
El cuarto parámetro nos permite indicar cuantas instrucciones
queremos desensamblar. Si pasamos un 0, la función intentará
desensamblar tantas instrucciones como pueda y devolverá el número de
instrucciones desensambladas, el cual, en este ejemplo, almacenamos en
count.
ins es un parámetro de salida que se rellena con todas
las instrucciones ensamblador que el desensamblador ha sido capaz de
decodificar del buffer que hemos pasado como parámetro. Por cada
instrucción se genera una entrada en el array de instrucciones
ins. Observad que, en general, cada una de estas
instrucciones se corresponde con varios valores numéricos de entrada,
especialmente para plataformas CISC como Intel.
MOSTRANDO EL ENSAMBLADOR
Una vez que hemos desensamblado nuestros datos tenemos que mostrarlos
en pantalla. Sabemos que nuestro buffer contendrá count
instrucciones y que ins será una matriz con
count instrucciones, así que solo tenemos que hacer un
bucle que imprima la información asociada a cada una de las
instrucciones. Esto es lo que hace el bucle principal del programa:
for (j = 0; j < count; j++) {
printf("0x%lx:\t%s\t\t%s\n",
ins[j].address,
ins[j].mnemonic,
ins[j].op_str);
}En este caso estamos imprimiendo la dirección asociada a la
instrucción (campo address). El mnemonico (campo
mnemonic) o código ensamblador asociado a la instrucción,
seguido de los operadores asociados a esa instrucción (campo
op_str).
La dirección, en nuestro caso se corresponde con el offset en el
array, ya que pasamos un cero al cuarto parámetro de
cs_disasm. Podéis ver que pasa si modificáis el programa y
pasáis como cuarto parámetro 0x40000 por ejemplo.
MEJORANDO NUESTRO DESENSAMBLADOR
La verdad que está genial programar nuestro propio ensamblador en unas pocas líneas de código, sin embargo, aunque el resultado es mucho mejor que la secuencia de números que teníamos al principio, aún no está nada claro que es lo que hace el código, así que vamos a implementar algunas mejoras.
Para ello, tenemos que decirle al desensamblador que necesitamos más detalles de cada instrucción, lo que conseguimos activando una de las opciones que nos ofrece Capstone:
cs_open (CS_ARCH_X86, CS_MODE_64, &h);
cs_option(h, CS_OPT_DETAIL, CS_OPT_ON); Al configurar esta opción, Capstone va a rellenar un campo
adicional en la estructura cs_insn con importantes detalles
sobre cada una de las instrucciones. En nuestro caso, vamos a intentar
decodificar los valores inmediatos que estamos cargando en la pila… esos
PUSH de números super largos. Para ello añadimos el
siguiente bloque de código después de imprimir la instrucción
ensamblador:
cs_detail *d = ins[j].detail;
if (d->x86.operands[0].type == X86_OP_IMM) {
char *tmp = (char *)&d->x86.operands[0].imm;
printf (" ; %s\n", tmp);
} else printf ("%s", "\n");Lo primero que hacemos es obtener un puntero a los detalles de la
instrucción… esto es básicamente para hacer el código que sigue más
corto. La estructura cs_details nos da información sobre
todos los operadores de la instrucción para el caso de PUSH
tenemos un solo operador cuyos detalles se almacenarán en la entrada
asociada al primer operador (valor 0).
Ahora comprobaremos si el tipo de operador es
X86_OP_IMM, es decir, si se trata de un direccionamiento
inmediato o lo que es lo mismo, si estamos usando un valor numérico
directamente.
NOTA
Los procesadores soportan muchas formas de acceder a los datos que se suelen conocer como modos de direccionamiento. Los más comunes son: * Inmediato: El operador es una constante numérica * Registro: El operador es un registro * Indirecto: El operador es el contenido de una posición de memoria * Indexado: El operador es el contenido de una posición de memoria que se calcula usando los valores de los registros que se especifican. * Relativo a PC: El operador es el valor del contador de programa más la constante que asociada. Se puede ver como un direccionamiento indexado utilizando como registro base el contador de programa.
En nuestro caso, sabemos que esos números son caracteres ASCII imprimibles así que simplemente accedemos a ellos como si fueran una cadena de caracteres y los imprimimos.
Con esta modificación, la salida para nuestro código de ejemplo sería:
> echo -e "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\ \xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80" | ./test02 + 24 bytes leidos 0x0: xor eax, eax 0x2: push rax 0x3: push 0x68732f2f ; //sh 0x8: push 0x6e69622f ; /bin 0xd: mov ebx, esp 0xf: push rax 0x10: push rbx 0x11: mov ecx, esp 0x13: mov al, 0xb 0x15: int 0x80 ;*
Veréis que en la última instrucción se imprime algo raro. La última
instrucción también utiliza un direccionamiento inmediato para su primer
operador 0x80, si bien no representa una cadena de
caracteres.
En nuestra aplicación final tendremos que comprobar si el valor del operador es una cadena o no, e imprimir la información de forma adecuada, pero por ahora vamos a mantener el código sencillo para que resulte más fácil seguir el funcionamiento del programa.
ENTENDIENDO EL SHELLCODE
Ahora ya nos resultará más sencillo entender que es lo que hace este
shellcode. Pero para poder entender el ensamblador debemos primero
entender como funciona la llamada al sistemas execve. El
prototipo de esta llamada es el siguiente:
int execve(const char *pathname, char *const _Nullable argv[],
char *const _Nullable envp[]);Como podéis ver, la llamada al sistema recibe 3 parámetros. El
primero es el nombre del programa que queremos ejecutar. Esta es una
cadena de caracteres conteniendo /bin/sh… ya que se trata
de un shellcode.
El segundo es el array de parámetros, donde el primero de ellos es el nombre del programa que vamos a ejecutar. Como muchos sabréis, el primer parámetro de cualquier programa C es el nombre del programa que estamos ejecutando.
Finalmente el tercer parámetro, es una lista de las variables de
entorno que queremos definidas al ejecutar el programa. Este valor, para
shellcodes normalmente lo dejamos vacío apuntando a
NULL.
Lo siguiente que tenemos que saber es que este shellcode es para
plataformas i386 o si lo preferís, plataformas Intel de 32bits. Eso lo
podemos deducir fácilmente por el uso de int 0x80 para
ejecutar la llamada al sistema (al final del código).
Para este tipo de plataformas, los parámetros a la llamada al sistema
se tienen que pasar en los registros : RBX,
RCX y RDX
Sabiendo todo esto vamos a analizar nuestro código de ejemplo.
ANALIZANDO EL ENSAMBLADOR
Lo primero que hacemos es almacenar un cero en la pila. La
instrucción xor realiza un or exclusivo entre
los dos parámetros que recibe y almacena el resultado en el primero de
ellos. Cuando los dos parámetros son iguales, el resultado de
xor es cero. Esta es una forma de inicializar un registro a
cero más eficiente y más corta (y que no requiere el uso de ceros).
xor eax, eax ;
push raxA continuación metemos nuestra cadena de caracteres en la pila a cachos y al revés.
push 0x68732f2f ; //sh
push 0x6e69622f ; /binTeniendo en cuenta que la pila crece hacia las direcciones bajas, el contenido de la pila en este momento sería:
SP + 0x08 | 0
SP + 0x04 | 0x68732f2f //sh
SP | 0x6e69622f /binComo podéis ver, al final de estas 4 instrucciones el puntero de pila
SP apunta al principio de la cadena /bin//sh\0
que es justo lo que necesitamos para ejecutar la shell. Así que
almacenamos este valor en el primer parámetro de la llamada al sistema
que será EBX
NOTA: Observad como en lugar de insertar
/bin/shel shellcode inserta/bin//sh. De esta forma se consigue utilizar el cero recién insertado en la pila por el comando anterior como terminador de la cadena, evitando de esta forma el uso de bytes nulos.
mov ebx, esp ; Primer parámetroAhora tenemos que construir el segundo parámetro que es un array de punteros a cadenas, siendo la primera de las cadenas el nombre del programa que vamos a ejecutar. Como antes, metemos en la pila los valores que nos interesan en orden inverso.
push rax ; NULL
push rbx ; Nombre del programa
mov ecx, esp; Segundo parámetroAsí el segundo parámetro en ECX apunta al array de
punteros que hemos creado en la lista.
SP + 0x08 | 0
SP + 0x04 | 0x68732f2f //sh
SP | 0x6e69622f /bin <- Param1 (RBX)
SP + 0x08 | 0 <- argv[1]
SP + 0x08 | RBX <- argv[0] (RCX)En este punto ya tenemos todos nuestros datos listos para ejecutar
execve, lo cual hacemos llamando al sistema con el valor
0x0b.
mov al, 0xb
int 0x80 Notad que en este caso, no hemos inicializado el valor de
RDX que debería ser NULL.
BYTES NULOS
Habréis notado que en varias ocasiones hemos dicho que el shellcode hace esto o esto oro para evitar el uso de bytes nulos o ceros. Muchos sabréis la razón de ello, pero por si acaso no habéis leído nada acerca de buffer overflows y exploits os lo explicamos en un periquete.
Los buffers overflow son quizás la vulnerabilidad más común utilizada
para ejecutar shellcodes. Los buffer overflow pueden ocurrir por
distintas razones pero una de las más comunes es el uso de la función
strcpy usando como origen datos introducidos por el usuario
sin sanear.
La función strcpy copiará en el buffer que recibe como
primer parámetro todos los datos del buffer que recibe como segundo
parámetro hasta que encuentre un byte nulo, vamos un 0. Lo
que esto significa es que, si el segundo buffer introducido por el
usuario contiene el shellcode a ejecutar tras explotar ese buffer
overflow, el mencionado shellcode no puede contener ningún cero ya que
de lo contrario, strcpy pararía de copiar los valores al
encontrarlo y parte del shellcode no se copiaría.
Hoy en día, con todas las medidas de seguridad que ofrecen los sistemas modernos es bastante difícil explotar un buffer overflow, sin embargo, si estudiáis shellcodes veréis código que parece excesivamente largo o complicado y a priori puede parecer raro, sin embargo, en la mayoría de los casos esto es debido a la necesidad de eliminar ceros del código máquina generado.
Podríais pensar que es una pérdida de tiempo prestar atención a estas cosas ya que, como os acabamos de decir, este tipo de exploits son casi imposibles hoy en día. Bueno, existe una salvedad a esta afirmación, son casi imposibles hoy en día en servidores o desktops… pero cuando se trata de routers u otros dispositivos embebidos la cosa cambia. Eventualmente estos dispositivos incorporarán todas las medidas de seguridad de sus hermanos mayores… pero entonces habrá un nuevo hermano pequeño en el que todas estas cosas vuelvan a ser relevantes… así que no es mala cosa entender como funcionaban las cosas hace unos años.
OTRO EJEMPLO
Veamos otro ejemplo de shellcode:
$ echo -e "\xb8\x3b\x00\x00\x00\x48\x8d\x3d\x08\x00\x00\x00\x48\ \x31\xf6\x48\x31\xd2\x0f\x05\x2f\x62\x69\x6e\x2f\x73\x68\x00" | ./test02 + 29 bytes leidos 0x0: mov eax, 0x3b 0x5: lea rdi, [rip + 8] 0xc: xor rsi, rsi 0xf: xor rdx, rdx 0x12: syscall
Este es otro shellcode de ejemplo. Este no es probable que lo veáis en un exploit (veis todos esos ceros en la secuencia del bytes?… pues eso) pero nos va a resultar útil para mejorar nuestro programa.
La salida de nuestro programa para este shellcode tiene dos problemas. El primero es que hemos leído 29 bytes, pero solo estamos mostrando 20. El segundo es que la instrucción en el offset 5 contiene un operador con un direccionamiento relativo a contador de programa y nos resultaría útil saber cual es el valor final al que apuntará la expresión.
RESOLVIENDO EL DIRECCIONAMIENTO RELATIVO
Vamos a comenzar mejorando la forma en la que mostramos las instrucciones con direccionamiento relativo al contador de programa. Para ello vamos a utilizar de nuevo el campo de detalles de las instrucciones.
Capstone maneja el direccionamiento relativo a contador de programa como un operador con memoria. Para esos casos, el campo de detalles nos ofrece la siguiente información:
base: Este es el registro base usado para el acceso a memoria. En nuestro caso este registro va a serRIP, pero en el caso general de direccionamiento indexado puede ser otro registro.indexyscale: Estos valores son específicos del direccionamiento indexado y nos permite acceder a elementos en un array (lista de elementos del mismo tamaño). En este casoindexes el índice en el array yscaleel tamaño de los elementos.disp: Esta es una constante que se añadirá al cálculo anterior a modo de offset.
Veamos un par de ejemplos de instrucciones con operadores que acceden a memoria para ver que forma toman cada uno de estos elementos:
mov rax, [rbp - 0x10]. Este es un típico caso de accesso a variables locales en una función. El registro base en este caso esRBPy0x10es el desplazamientodisp.lea rdi, [rsi + rbx*4]. Este es un ejemplo típico de acceso a una array de palabras de 32 bits (scalees 4) contenido en el registroRSIy usando como índiceRBX. La instrucción almacenará enRDIel valorRSI + RBX * 4lea rdi, [rip + 0x10]. Esta instrucción cargaráRDIcon la direcciónRIP + 0x10. Teniendo en cuenta queRIPapunta a la siguiente instrucción.
PROCESANDO DIRECCIONAMIENTO RELATIVO
En el caso de nuestro shellcode de ejemplo, tenemos que examinar los valores del segundo operador (índice 1).
0x5: lea rdi, [rip + 8]
Como podemos ver, el segundo operador [rip + 8] es un
operador de acceso a memoria que utiliza RIP como registro
base junto con un desplazamiento de 8 bytes. Esta
instrucción en concreto ocupa la friolera de 7 bytes, por lo que el
contador de programa cuando el procesador vaya a ejecutarla apuntará a
5+7=12 ->0xc. Si le sumamos 8, estaríamos
apuntando a 0x14.
Veamos como implementar esto en nuestro código.
if (d->x86.operands[1].type == X86_OP_MEM &&
d->x86.operands[1].mem.base == X86_REG_RIP) {
long ptr1 = ins[j].address + d->x86.operands[1].mem.disp + ins[j].size;
long ptr2 = ((long)buf + ptr1 ); // Create a label for this
printf ("; 0x%lx ", ptr1);
printf (" -> '%s'", (char*)ptr2);
}En este caso, primero comprobamos que el operando se refiere a un
modo de direccionamiento de memoria, para a continuación comprobar de
que tipo de direccionamiento se trata. Como ya sabemos, para un
direccionamiento relativo a contador de programa, el registro base debe
ser RIP (el contador de programa), así que eso es lo que
comprobamos.
Una vez que hemos identificado la instrucción vamos a mostrar los datos de una forma un poco más útil. Para ello, primero calculamos lo que sería el valor del operador. Esto es:
0x5: lea rdi, [rip + 8]; 0x0c: xor ... ins[j].address + ; Dirección de la instrucción actual (0x5) ins[j].size + ; Tamaño de la instrucción actual (0x7) d->x86.operands[1].mem.disp ; Parámetro instrucción (0x8)
Para calcular el valor primero tenemos que determinar cual es el
valor del contador de programa. Para plataformas intel, el contador de
programa siempre apunta a la siguiente instrucción. Por tanto, el valor
de RIP para la instrucción en 0x5 es
0x5 + la longitud de la instrucción, que en este caso es 7
como ya os explicamos. Es decir, RIP vale 0xc
en el momento de ejecutar la instrucción en la dirección
0x5.
Ahora solo tenemos que sumar el valor del desplazamiento del
operador. En este caso 8 (el valor que sumamos a
rip en la instrucción lea). Por lo tanto, la
instrucción está almacenando en el registro RDI el valor
0x14… Y ese es el primer valor que mostramos. Si ahora
asumimos que esa dirección de memoria contiene una cadena de caracteres,
podemos intentar imprimirla. Con este cambio, la salida de nuestro
programa será ahora:
$ echo -e "\xb8\x3b\x00\x00\x00\x48\x8d\x3d\x08\x00\x00\x00\ \x48\x31\xf6\x48\x31\xd2\x0f\x05\x2f\x62\x69\x6e\x2f\x73\x68\x00" | ./test02 + 29 bytes leidos 0x0: mov eax, 0x3b 0x5: lea rdi, [rip + 8]; 0x14 -> '/bin/sh' 0xc: xor rsi, rsi 0xf: xor rdx, rdx 0x12: syscall
Ahora podemos ver claramente la cadena /bin/sh la cual
estará almacenada en la posición 0x14… la cual no se muestra… Oops!!
MOSTRANDO TODOS LOS DATOS
Lo que pasa con el shellcode anterior es que el valor en la dirección
0x14 no se corresponde con ninguna instrucción válida, y
Capstone termina el desensamblado en ese punto. En ocasiones,
por casualidad encontraremos valores que si se corresponden a
instrucciones, aunque se trate de datos y el resultado será un código
sin sentido. En esos casos tenemos que añadir más inteligencia a nuestra
aplicación para procesar cada bloque del buffer de la forma
correcta.
Lo que si podemos hacer fácilmente, y funcionará bastante bien para mostrar shellcodes, es mostrar como datos cualquier cosa que se encuentre desde que falla el desensamblado hasta el final de los datos que nos han proporcionado.
En este caso, la última instrucción que hemos desensamblado es
syscall que tiene un tamaño de 2 bytes y se encuentra en la
dirección 0x12, así que mostraremos todos los datos a
partir de 0x14 (0x12 + 0x2) hasta
completar los 29 bytes que hemos leído en este caso.
Observad, que al salir del bucle en el que imprimimos las
instrucciones, j apunta a la primera entrada, la cual es
una entrada no válida. Es decir, la última instrucción valida que hemos
mostrado es j-1 y por tanto, el siguiente código mostrará
todo lo que hay después de la ultima instrucción como una cadena:
long data = (long)ins[j-1].address + ins[j-1].size;
printf ("Datos:\n");
if (data < offset)
printf ("0x%lx %s\n", data, (char*)buf + data);Con este cambio, la salida de nuestro programa sería ahora:
$ echo -e "\xb8\x3b\x00\x00\x00\x48\x8d\x3d\x08\x00\x00\x00\ \x48\x31\xf6\x48\x31\xd2\x0f\x05\x2f\x62\x69\x6e\x2f\x73\x68\x00" | ./test02 + 29 bytes leidos 0x0: mov eax, 0x3b 0x5: lea rdi, [rip + 8]; 0x14 -> '/bin/sh' 0xc: xor rsi, rsi 0xf: xor rdx, rdx 0x12: syscall Datos: 0x14 /bin/sh
Observad que tanto en esta modificación como en las anteriores hemos supuesto que los datos son cadenas de caracteres y simplemente los hemos mostrado, sin embargo ese no tiene porque ser el caso y el programa, tal y como está fallará en muchos casos en los que eso no sea cierto En general, el programa debería analizar los datos y determinar si el contenido es una cadena de caracteres o no, antes de imprimirla. En caso de que no lo sea deberíamos hacer un volcado hexadecimal de la misma.
Dejamos esta modificación como ejercicio para los lectores. Añadiremos esta capacidad en entregas posteriores, pero mientras esperáis por el próximo número os podéis ir entreteniendo :).
COLOFÓN
Hasta aquí esta primera entrega de Aprende Hacking escribiendo tus propias herramientas. En esta entrega hemos aprendido que es un shellcode y hemos escrito un sencillo programa para convertirlos en ensamblador a partir de la forma en la que normalmente se encuentra en los exploits para distintas vulnerabilidades. Para ello hemos utilizado una librería que hace el trabajo duro y hemos visto como aún usando esa librería, tenemos que escribir algo de código extra para que nuestra herramienta resulte útil.
Nuestro volcador de shellcodes no pita mal, pero aún hay algunas mejoras que debemos incluir con las que explorar nuevos conceptos. Nos vemos en la próxima entrega.
■



Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.